
𝑁𝑜𝑡𝑒𝑏𝑜𝑜𝑘
로지스틱 회귀 본문
[ 목차 ]
로지스틱 회귀
: 데이터가 어떤 범주에 속할 확률을 0에서 1사이의 값으로 예측한 뒤 그 확률에 따라서 가능성이 특정 기준치 이상인 경우 해당 클래스로 분류해주는 지도 학습 알고리즘

- x가 연속형 변수이고, y가 특정 값이 될 확률이라고 설정한다면, 왼쪽 그림과 같이 선형으로 설명하긴 쉽지 않아 보인다 확률은 0과 1사인데, 예측 값이 확률 범위를 넘어 갈 수 있는 문제가 있다
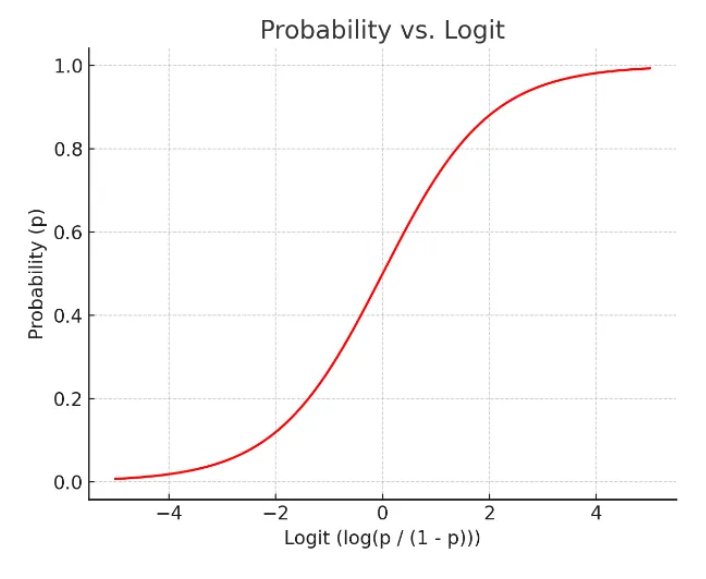
- 하지만 오른쪽 그림은 s자 형태의 함수를 적용하면 잘 설명한다고 할 수 있을 것 같다
함수
- 시그모이드 함수 중 하나로 립러닝에서 다시 활용 = 값을 계산하면 확률이 도출 ‼️

- 위 식을 p에 대해서 정리하여 다음과 같이 표현 가능

🟢로짓의 장점 : 어떤 값을 가져오더라도 반드시 특정 사건이 일어날 확률
(Y값이 특정 값일 확률)이 0과 1안으로 들어오는 특징을 가짐
- 로짓과 기존 선형회귀의 우변을 합쳐 다음과 같은 식을 도출

- 양변에 자연지수 e를 취하면

- 해석 : x값이 $ w_1$만큼 증가하면 오즈비는 $ w_1$ 만큼 증가한다

🟢 로지스틱함수는 가중치 값을 안다면 x값이 주어졌을 때 해당 사건이 일어날 수 있는 p의 확률을 계산할 수 있다
이때, 확률 0.5를 기준으로 그보다 높으면 사전이 일어남 (P(Y) = 1),
그렇지 않으면 사건이 일어나지 않음 (P(Y) = 0)으로 판단하여 분류 예측에 사용
자주 쓰는 함수
- sklearn.linear_model.LogisticRegression : 로지스틱회귀 모델 클래스
- 속성
- classes_ : 클래스(Y)의 종류
- n_features_in_ : 들어간 독립변수(X) 개수
- feature_names_in_ : 들어간 독립변수(X)의 이름
- coef_ : 가중치
- intercept_ : 바이어스
- 메소드
- fit : 데이터 학습
- predict : 데이터 예측
- predict_proba : 데이터가 Y = 1일 확률을 예측
- sklearn.metrics.accuracy : 정확도
- sklearn.metrics.f1_socre : f1_score
- 속성
📌 정리
- 장점 : 역시 직관적이며 이해하기 쉽다
- 단점 : 복잡한 비선형 관계를 모델링하기 어려울 수 있음
- Python 패키지
- sklearn.linear_model.LogisticRegresson
회귀, 분류 정리해보기
- 선형회귀와 로지스틱회귀의 공통점
- 모델 생성이 쉬움
- 가중치(혹은 회귀계수)를 통한 해석이 쉬운 장점이 있음
- X변수에 범주형, 수치형 변수 둘 다 사용 가능
- 선형회귀와 로지스틱 분류 차이점

'머신러닝 🦾' Related Articles
more



